



5月12日,江蘇省委網(wǎng)信辦對外公布江蘇省第七批通過國家生成式人工智能服務(wù)備案的5款大模型,“荀子古籍大語言模型”位列其中。
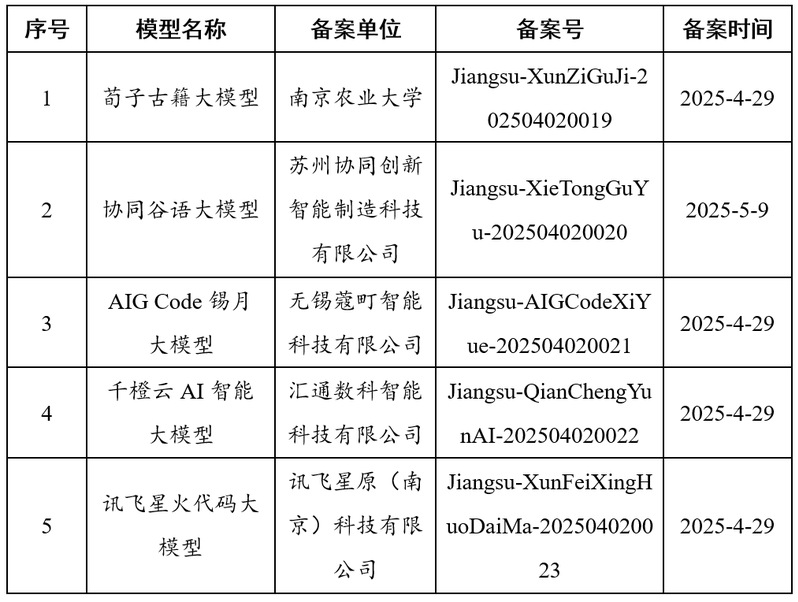
荀子古籍大語言模型由南京農(nóng)業(yè)大學王東波教授團隊主導研發(fā),是江蘇省首個完全以高校為主體完成國家生成式人工智能服務(wù)備案的大語言模型。該模型依托南京農(nóng)業(yè)大學的高性能算力基礎(chǔ)設(shè)施支持,結(jié)合課題組在古籍數(shù)字化領(lǐng)域??十余年的數(shù)據(jù)積累,實現(xiàn)了古籍傳承與人工智能技術(shù)的深度融合。這一成果不僅彰顯了高校在科研創(chuàng)新中的重要地位,也為江蘇省大模型產(chǎn)業(yè)注入了學術(shù)化、專業(yè)化的新動能。??

作為古籍智能處理領(lǐng)域的開創(chuàng)性成果,“荀子”是國內(nèi)首個全開源的專注于古籍活化利用的垂直大語言模型。其核心功能涵蓋古籍智能標引、信息抽取、詩歌生成、高質(zhì)量翻譯、詞法分析、自動標點等場景。例如,模型可自動識別《史記》中的人物關(guān)系并生成知識圖譜,或?qū)ξ淳渥x的文言文進行精準斷句和翻譯,極大提升了古籍在廣大群眾中的推廣傳播效率。此外,該模型的開源性、公益性特點,使其成為古籍活化的標桿工具,為古籍數(shù)字化研究提供了更加堅實的基礎(chǔ)。
在全國范圍內(nèi),荀子古籍大語言模型是第二個以高校為主體成功備案的大語言模型。研發(fā)團隊依托國家社科基金重大項目,構(gòu)建了覆蓋《四庫全書》等傳世古籍的40億字混合語料庫,并通過創(chuàng)新的“古籍-現(xiàn)代漢語混合訓練”技術(shù),突破了通用大模型在古文理解與生成中的瓶頸。這一成就不僅填補了古籍領(lǐng)域大語言模型的空白,更標志著高校在人工智能技術(shù)攻關(guān)中的重要作用,為后續(xù)產(chǎn)學研合作提供了示范。
王東波教授介紹,荀子古籍大語言模型的備案,具有三大核心價值的體現(xiàn):一是以南京農(nóng)業(yè)大學學術(shù)積累為根基,推動古籍研究從數(shù)字化向智能化轉(zhuǎn)型的學術(shù)引領(lǐng);二是以首創(chuàng)“ACHeval評測基準”和混合訓練策略,兼顧古文處理與現(xiàn)代漢語能力的技術(shù)突破;三是通過全面開源模式降低古籍研究門檻,助力全球?qū)W者探索中華文明的文化傳承。
據(jù)悉,荀子古籍大語言模型將深化人工智能技術(shù)在??古籍整理、保護、轉(zhuǎn)化、增強上的應(yīng)用,進一步推動古籍活化在人工智能時代的創(chuàng)新性發(fā)展。
閱讀次數(shù):635
【 轉(zhuǎn)載本網(wǎng)文章請注明出處 】
